Parallel Series 07 - Problemas de concurrencia
Cuando los threads luchan por acceder a los mismos recursos

Las nuevas Concurrent Collections
En un mundo en el que los procesos ya no son secuenciales sino paralelos, es cada vez más posible encontrarnos con problemas de concurrencia al acceder a recursos compartidos. Conceptualmente hablando, esto es algo a los que los desarrolladores ya estamos acostumbrados cuando trabajamos con gestores de bases de datos como Oracle o SQL Server, ya que varios usuarios pueden acceder o modificar la información al mismo.
Sin embargo, la gran mayoría de los desarrolladores pocas veces hemos tenido que lidiar con bloqueos en colecciones en menoria, ya que no todo el mundo crea aplicaciones en las que varios threads acceden a recursos compartidos. De hecho, si alguna vez has lo tenido que hacer sabrás perfectamente que antes de la aparición de la TPL era una de las disciplinas más complejas dentro del desarrollo de software, casi tanto como nombrar bien las cosas (*). Es algo que favorece la calvície, y créeme, lo digo por experiencia :)
(*) There are only two hard things in Computer Science: cache invalidation and naming things.
Sin embargo, desde la aparición de la TPL en el .NET Framework 4.0 es mucho más sencillo desarrollar aplicaciones que ejecuten procesos en paralelo o de forma asíncrona, pero esto conlleva que en ocasiones nos olvidemos que hay algunos threads que se ejecutan al mismo tiempo, y esto podría llevar a producir efectos no deseados cuando se trata de acceder a recursos compartidos, como una colección de elementos en memoria.
Por ejemplo: supongamos un escenario en el que tenemos una lista de clientes en memoria y un par de tareas (Task) que acceden a esa colección. La primera tarea podría estar verificando si todos los clientes cumplen una condición X, y si no la cumplen eliminar el cliente de la colección. Mientras tanto la segunda tarea podría estar actualizando alguna propiedad de los clientes, como la edad.
Un escenario real
Encierra este escenario algún peligro? A priori podemos pensar que no. Basta con que la segunda tarea verifique si el cliente existe en la colección antes de actualizarlo. Seguro? Pues no. Al menos no basta si la colección que estamos usando no es una de las nuevas definidas dentro del namespace System.Collections.Concurrent. Y para verlo mejor, hagamos un pequeño ejemplo con código, que es lo que nos gusta a todos.
Paso 1 – Definir una Clase Customer
|
|
Paso 2 – Crear un Dictionary
|
|
Paso 3 – Crear 100.000 clientes de ejemplo
|
|
Paso 4 – Definir 2 métodos que compitan entre si
Ahora, vamos a complicar un poco más el ejemplo y crearemos dos métodos que simulen el borrado y la actualización de los objetos que contiene la colección. Luego llamaremos a éstos métodos para 100 objetos aleatorios de forma paralela para ver que efectos se producen
|
|
Paso 5 - A jugar :)
Ejecutamos nuestra aplicación y si se produce una colisión puede pasar que obtengamos un bonito error como este, en el que básicamente se intenta acceder a un elemento de la colección que ya no existe (Si no se produce a la primera, repite la prueba hasta que lo veas).
Y digo que puede pasar, pero no es seguro. Tal vez tengamos que repetir el proceso varias veces, y es que en un entorno en el que varios threads acceden a un recurso compartido nada nos asegura que se produzca el error. A veces pasa a la primera y a veces a la cuarta, pero hay que tener presente que cuando esté en producción siempre pasará en viernes por la tarde cinco minutos antes de empezar el fin de semana ;)
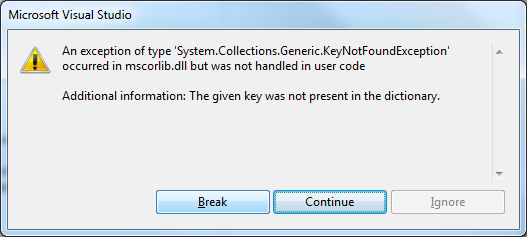
Error al intentar acceder a una cliente que ya no existe
Concretamente en la línea que incrementa la edad del cliente:
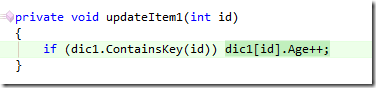
¿Pero cómo puede pasar esto?
Analicemos el porqué del error: ¿cómo es posible que no encuentre el elemento en la colección si precisamente en la línea anterior verificamos su existencia? Pues ahí está la gracia, que lo verificamos en la línea anterior. A nosotros -pobres developers- nos parece que la línea anterior en la que verificamos si existe y la línea siguiente en la que lo eliminamos van seguidas una detrás de otra, pero realmente en un entorno asíncrono hay todo un mundo entre ambas. Y eso es porque ambas líneas se ejecutan de forma separada, sin ningún tipo de bloqueo, no existe Transaccionalidad al estilo de las bases de datos, de modo que mientras el primer thread verifica que existe ese elemento en la colección y lo borra, llega el segundo thread y… ZASCA! Lo elimina.
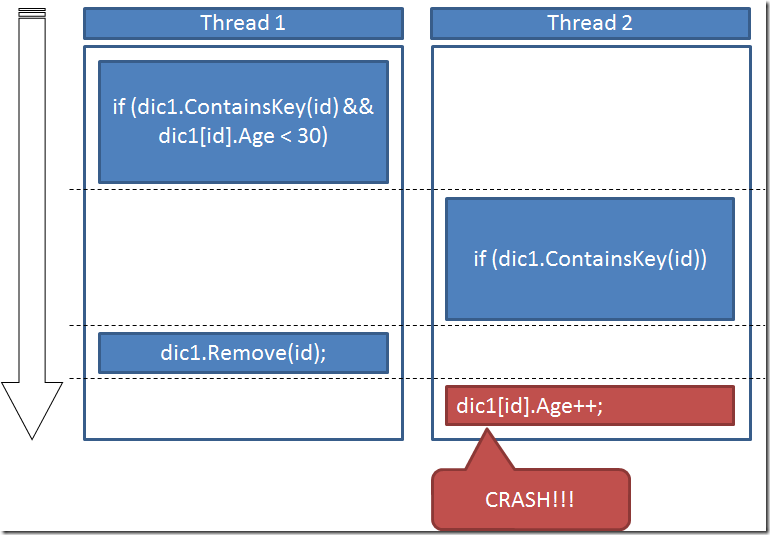
Esta es la explicación...
La nueva clase ConcurrentDictionary
Para lidiar con estos casos aparecen en escena un nuevo conjunto de colecciones especializadas en entornos multithreading. Una de las más populares es una variación del clásico Dictionary, el ConcurrentDictionary. Esta clase proporciona una série de métodos alternativos para agregar, modificar o eliminar elementos llamados TryAdd, TryUpdate o TryRemove. La ventaja de éstos métodos es que son transaccionales y proporcionan Atomicidad. Es decir, garantizan que en caso de que se invoquen, se ejecuten totalmente: O bien se añade/modifica/elimina el elemento de la colección o bien se devuelve el valor False porque no se ha podido realizar la operación. También proporciona un método TryGetValue que intenta obtener un elemento de la colección. Todos estos métodos implementan en su interior bloqueos (lock), para asegurar que nadie más accede al elemento mientras se realiza la operación solicitada.
Arreglando el ejemplo anterior :)
Vamos a modificar el ejemplo anterior usando esta nueva colección, para observar su comportamiento en el entorno anterior.
Paso 1 – Cambiamos Dictionary por ConcurrentDictionary
|
|
Paso 2 - Creamos 100.000 clientes de ejemplo
Al igual que hacíamos antes. Aquí podemos ver la primera diferencia, ya que usamos uno de los nuevos métodos TryXXX:
|
|
Paso 3 - Modificamos los 2 métodos que compiten
|
|
En el borrado usamos el método TryRemove que necesita el id del elemento a eliminar, y en caso que lo elimine con éxito, devuelve True y el objeto eliminado en el segundo parámetro out (de salida) del método. En caso que no lo elimine devuelve False y el valor default del objeto a eliminar en el segundo parámetro.
La actualización es un poco más compleja, ya que primero debemos asegurarnos de que el elemento a modificar existe en la colección mediante el método TryGetValue, que básicamente funciona igual que el método TryDelete anterior. Una vez hemos comprobado que dicho objeto existe en la colección creamos una réplica del cliente, modificamos su edad y llamamos al método TryUpdate, el cual se encarga de la modificación.
Es interesante notar que para que la modificación se realice correctamente debemos informar de la clave del objeto en la colección, el nuevo valor del objeto (en este caso la réplica del cliente a la que hemos modificado la edad) y un tercer parámetro que es el valor original del objeto, que es usado para comparar.
Paso 4 - A jugar de nuevo :D
Ejecutamos y si vamos a la ventana de consola podremos observar el resultado:
|
|
En la mayoría de los casos, obtenemos un error de lectura porque el elemento ya ha sido eliminado de la colección, pero en algunos casos el error se producirá en el método TryUpdate. Eso significa que la llamada a TryGetValue encuentra el elemento, pero cuando lo vamos a modificar éste ya no existe en la colección. Perfecto! :)
Conclusión
La ventaja de usar colecciones específicas en entornos multithreading es clara: Garantizan que el acceso a los recursos compartidos sea transaccional, al más puro estilo de las bases de datos. De acuerdo que su programación sea un poco más compleja, pero no tiene nada que ver con lo que se tenía que hacer antiguamente cuando no existía la TPL.
Por otro lado, el uso de estas colecciones debe hacerse sólo en aquelos casos en los que se accede a recursos compartidos, ya que si no, por un lado estamos complicando nuestro codigo y por otro lado un ConcurrentDictionary no es tan eficiente como lo és un Dictionary, sobre todo en entornos más de escritura que de lectura. Tenéis un post muy detallado al respecto del gran James (aka Black Rabbit) respecto a la diferencia de performance:
Espero sacar tiempo para otro post en el que explicar otras colecciones de este namespace, como las ‘BlockingCollection’ o las ‘’ConcurrentBag’, que son colecciones más especializadas. La primera está optimizada para escenarios dónde el mismo thread produce y consume objetos, mientras que la segunda ha sido especialmente diseñada para escenarios de productor-consumidor.